URLからドメインを簡単に取り出す方法【TEXTAFTER・TEXTBEFORE関数の使い方】
アクセス解析やリンク集計などで、URL 文字列からドメイン(ホスト名)だけを抽出したい場面は多いですよね。
ここでは最新 Excel 365 の関数 TEXTAFTER・TEXTBEFORE・IFERROR を組み合わせた1 行式を紹介し、その仕組みを丁寧に解説します。
1. サンプルデータを用意しよう
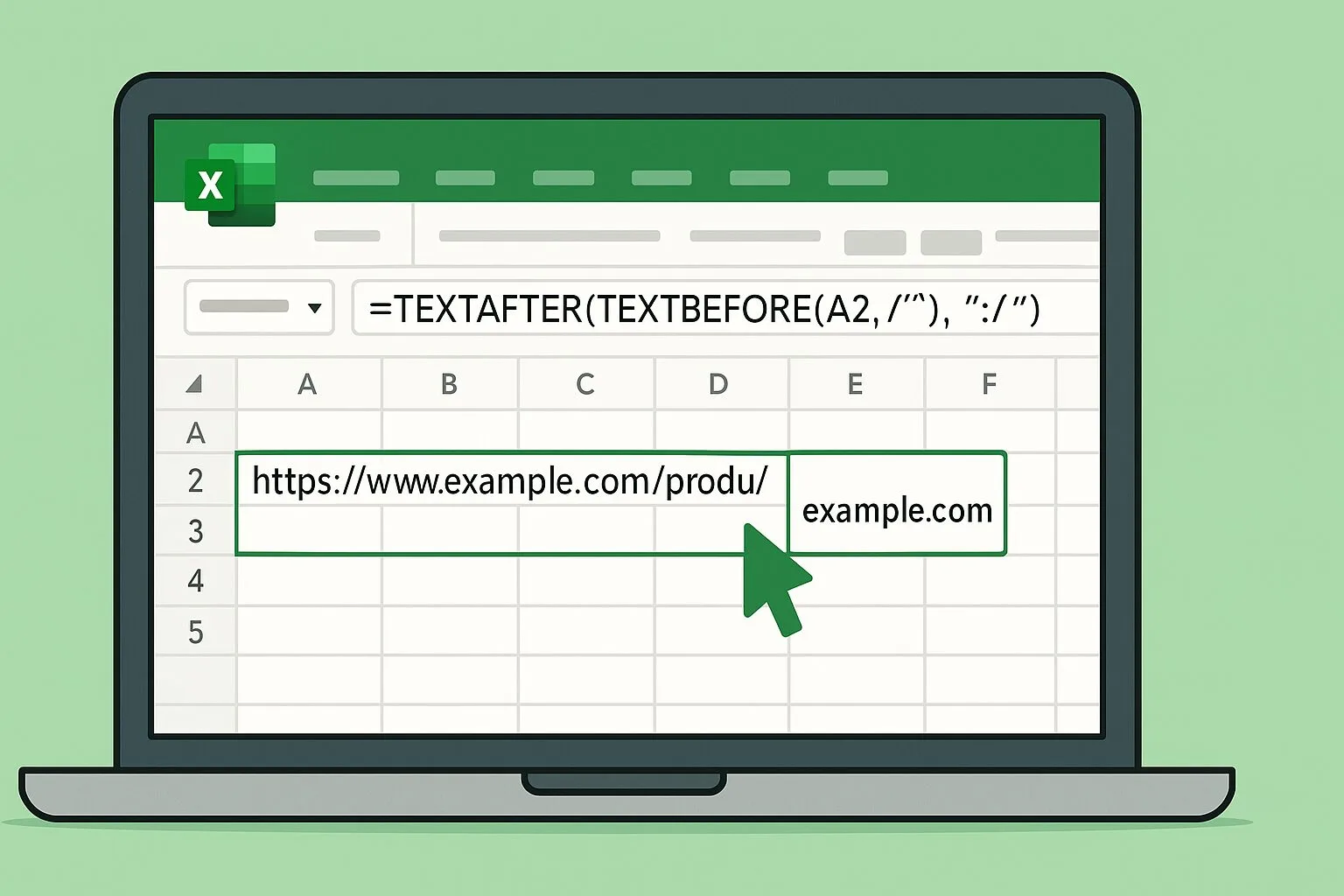
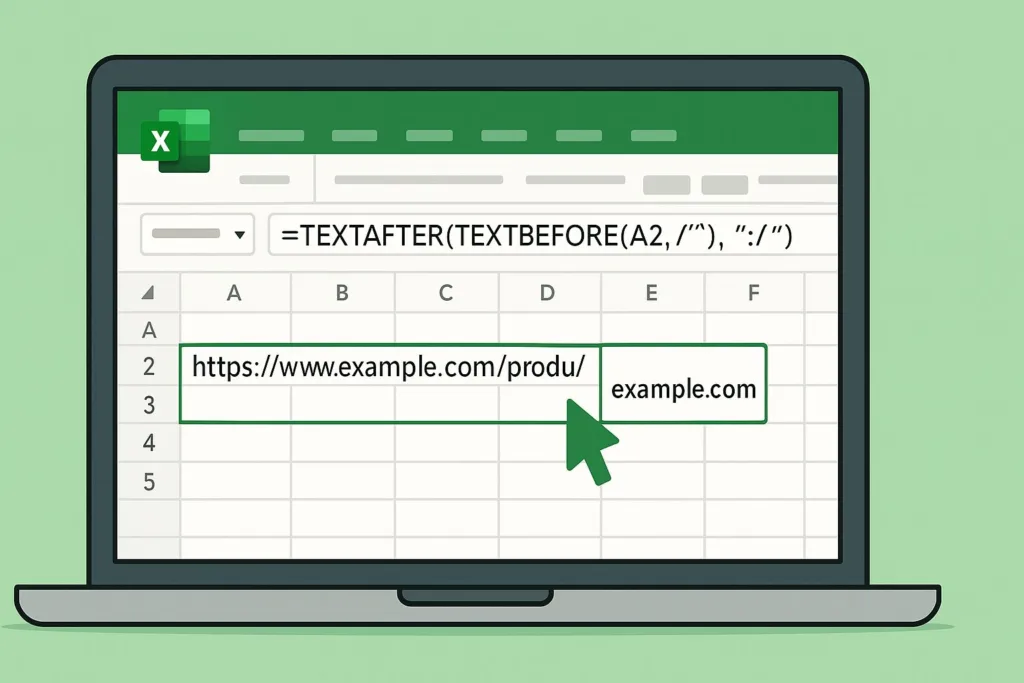
まずは下図のようなテスト表を作成してください。
セル A2:A4 に URL を入力し、B 列 にこれから紹介する式を入れて動作を確認します。
| URL (A列) | 取得結果 (B列) |
|---|---|
| https://www.example.com/product/123 | www.example.com |
| http://blog.example.co.jp | blog.example.co.jp |
| https://sub.domain.test.org/path/ | sub.domain.test.org |
2. 使う式(コピペ OK)
=IFERROR(TEXTBEFORE(IFERROR(TEXTAFTER(A2,"//"),A2),"/"),IFERROR(TEXTAFTER(A2,"//"),A2))
もしくは
=IFERROR(
TEXTBEFORE(
IFERROR(
TEXTAFTER(A2, "//"),
A2
),
"/"
),
IFERROR(
TEXTAFTER(A2, "//"),
A2
)
)・セル A2 を基準に書いているので、下方向へコピー/スピルすれば自動で行番号が変わります。
・LET を使っても同じ結果が得られます。式は以下のようになります。
=LET(
raw, A2,
noProto, IFERROR(TEXTAFTER(raw, "//"), raw),
domain, IFERROR(TEXTBEFORE(noProto, "/"), noProto),
domain
)- raw:元の URL(セル A2)
- noProto:先頭の「http://」「https://」を取り除いた文字列
- domain:最初の「/」より前の部分(=ドメイン)
3. ロジックを3ステップで分解
STEP 1 : TEXTAFTER(A2,"//")
https://www.example.com/product/123⇒www.example.com/product/123//cdn.jsdelivr.net/npm/axios⇒cdn.jsdelivr.net/npm/axios
「//」より右側を丸ごと取得します。
ただし「//」が含まれていない URL(cdn.jsdelivr.net/… のようなプロトコル省略型)では #N/A になるため、次の IFERROR で補正します。
STEP 2 : IFERROR(TEXTAFTER(A2,"//"), A2)
ここで“// が見つからないときは元の文字列そのもの”を返すように変換。
これでどんな表記ゆれでも “ドメイン以降を含む文字列” が得られます。
STEP 3 : TEXTBEFORE(…, "/")
www.example.com/product/123⇒www.example.comblog.example.co.jp⇒blog.example.co.jp
取得済み文字列の最初の「/」より左側を取り出せば、純粋なドメインが完成。
ここでも「/」が存在しないケースに備え、さらに IFERROR で値を保持しています。
4. なぜ2つの IFERROR が必要?
- 第1の IFERROR(内側) …
TEXTAFTERが#N/Aを返したときに代替としてA2を利用。 - 第2の IFERROR(外側) …
TEXTBEFOREが#N/Aを返したときに、内側の値を採用。
こうして「// 無し」「末尾 / 無し」どちらにも完全対応する頑丈な式になります。
コメント