
ExcelのFILTERXML関数入門 – 基本概念と使い方
本記事では、ExcelのFILTERXML関数について紹介します。FILTERXML関数は、XMLデータを解析し、特定の要素や属性を抽出するための強力な関数です。この記事を読めば、FILTERXML関数の基本的な使い方を理解し、実践的な例を試すことができるようになります。
FILTERXML関数の基本
FILTERXML関数は、Microsoft Excelの関数で、XMLデータから特定の要素や属性を抽出するために使用されます。XPathと呼ばれる言語を使って、データの中から条件に一致するノードを照会します。
以下は、FILTERXML関数の構文です。
=FILTERXML(xml, Xpath)
引数の説明:
- xml – フィルタリングするXMLデータの文字列。有効なXML形式である必要があります。
- Xpath – データから抽出する要素や属性に一致するXPath式。XMLノードを特定するための階層構造や軸を指定できます。
FILTERXML関数の使い方:基本例
次に、基本的な例を使って、FILTERXML関数の使い方を説明します。
以下のようなXMLデータがあるとします(セルA1などへセットし、そこへ「xmlデータ甲」などの名前を付ける)。
<books>
<book>
<title>Book1</title>
<author>Author1</author>
</book>
<book>
<title>Book2</title>
<author>Author2</author>
</book>
<book>
<title>Book3</title>
<author>Author3</author>
</book>
</books>
例: 要素を抽出
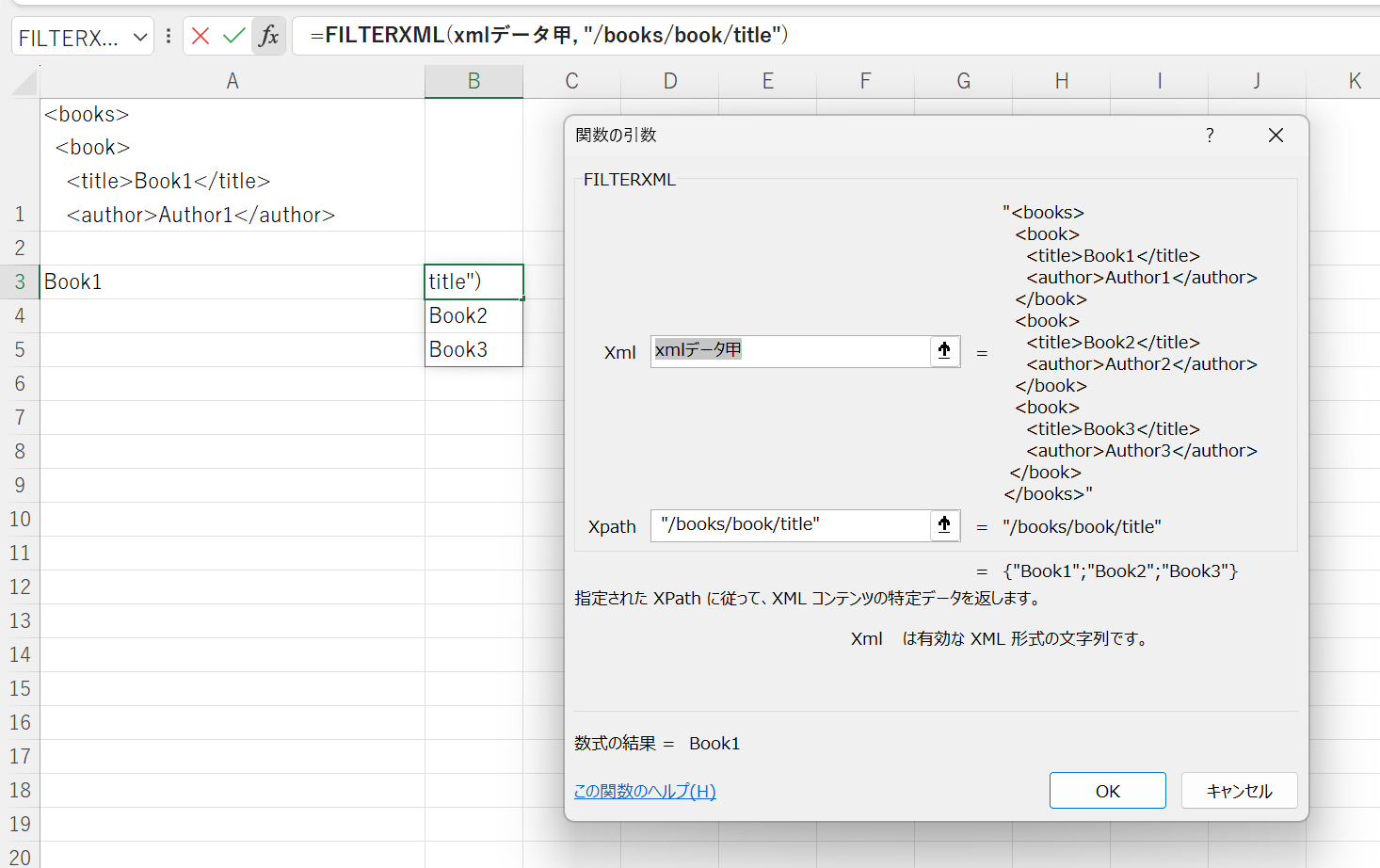
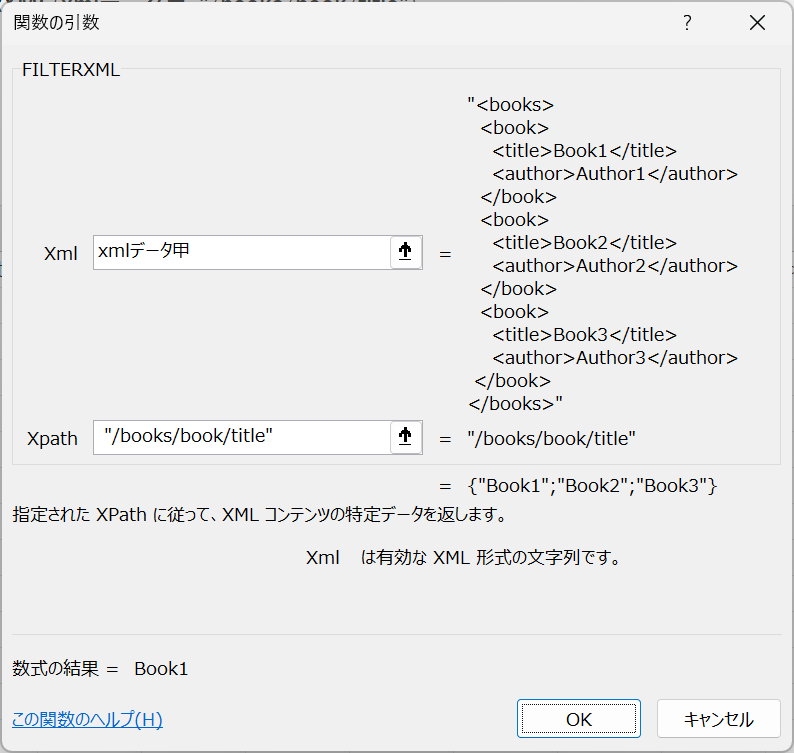
すべてのbook要素のtitleを抽出するには、以下のような式を使用します。
=FILTERXML(xmlデータ甲, "/books/book/title")
これにより、スピル機能を使って、以下のようなリストが返されます。
Book1 Book2 Book3
例: インデックスを使用し位置を指定して抽出[数値]
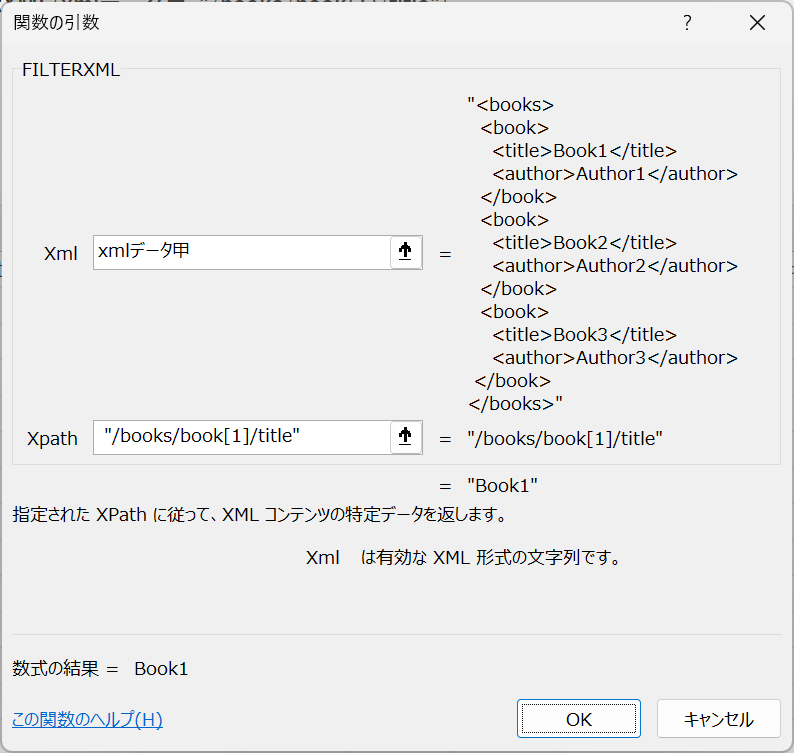
2番目のbook要素のtitleを抽出するには、以下のような式を使用します。
=FILTERXML(xmlデータ甲, "/books/book[2]/title")
これにより、「Book2」が返されます。XMLでの位置指定は1からスタートします。他の多くのプログラミング言語とは異なり0からのスタートではありません。
例: 属性を抽出(@)
XMLデータに属性が含まれている場合、@を利用して属性値を抽出することもできます。以下のXMLデータを考えてみましょう(セルC1などへセットし、そこへ「xmlデータ甲」などの名前を付ける)。
<books>
<book id="1">
<title>Book1</title>
<author>Author1</author>
</book>
<book id="2">
<title>Book2</title>
<author>Author2</author>
</book>
<book id="3">
<title>Book3</title>
<author>Author3</author>
</book>
</books>
第2のbook要素のid属性を抽出するには、以下のような式を使用します。
=FILTERXML(xmlデータ乙, "/books/book[2]/@id")
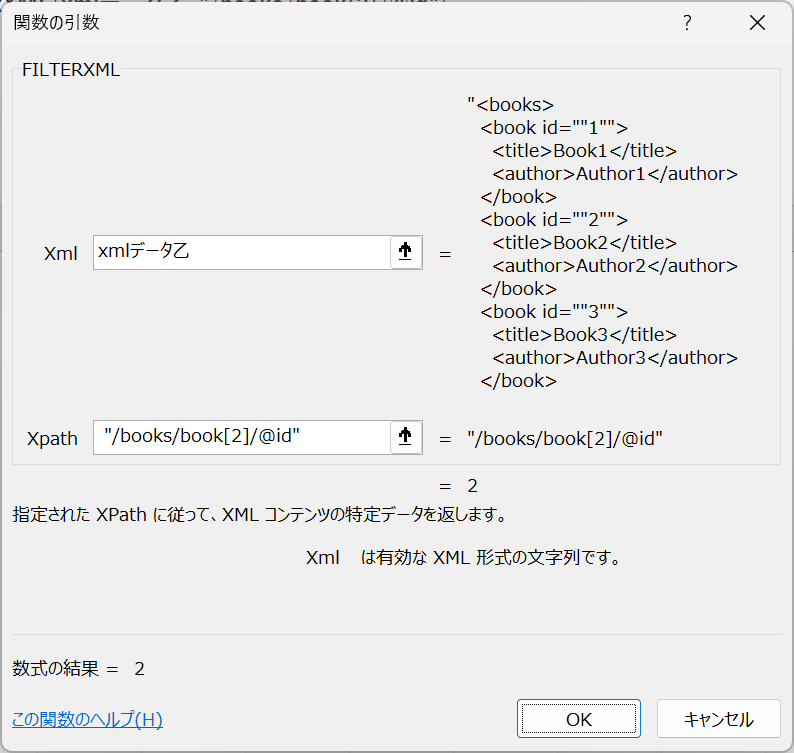
これにより、「2」という属性値が返されます。
次の記事

ExcelのFILTERXML関数とスピル機能を活用しよう | FILTERXML(2)
ExcelのFILTERXML関数とスピル機能を活用しようFILTERXML関数とスピル機能の活用Excelのスピル機能は、複数の結果を返す関数の結果を隣接するセルに自動的に配置する機能です。FILTERXML関数を使った場合、複数のXML...
www.helpaso.net
2023.05.14
コメント