
以下のサンプル表において、A列の数値データをC~H列へ1桁単位で分割させる手順をご紹介します。TEXT関数とMID関数を組み合わせて処理を実現します。
サンプルは「最大6桁」と仮定しています。
それ以上の桁数を採用する場合には1行目の桁数データを伸ばしてください。
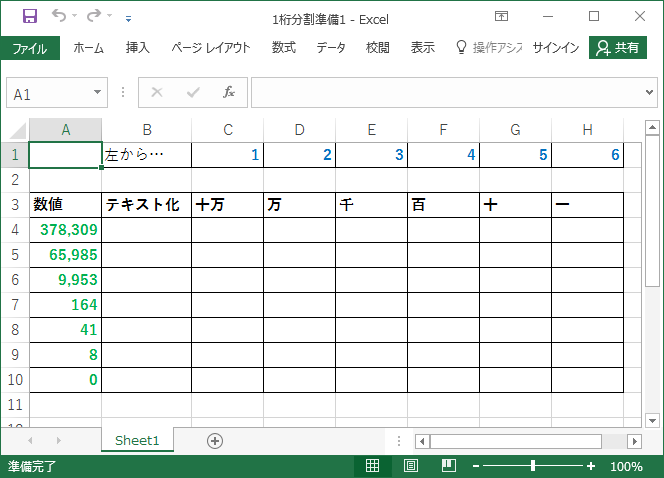
| 左から… | 1 | 2 | 3 | 4 | 5 | 6 | |
| 数値 | テキスト化 | 十万 | 万 | 千 | 百 | 十 | 一 |
| 378309 | |||||||
| 65985 | |||||||
| 9953 | |||||||
| 164 | |||||||
| 41 | |||||||
| 8 | |||||||
| 0 |
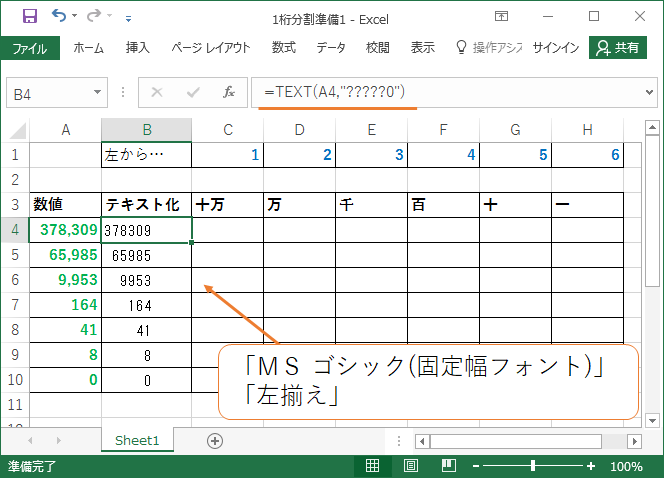
まずはセルB4に
=TEXT(A4,"?????0")
を作成して10行目までコピーしてください。
第一引数は「値」、第二引数は「表示形式」となっています。
A列の数値を「6桁の文字」にしています。
TEXT関数は数値データを、指定した表示形式を適用した状態の文字データへ変換する関数です。
今回はA列の数値を「6桁の文字」にします。
その場合は引数「表示形式」に「?を5個+0」を指定します。
関数を作成後はB列の書式を「MS ゴシック(固定幅フォント)」「左揃え」にして確認します。
上記の関数の効果により、不要な桁の部分には「スペース」がセットされました。
「游ゴシック」「MS Pゴシック」などのプロポーショナルフォントでは桁が揃いません。
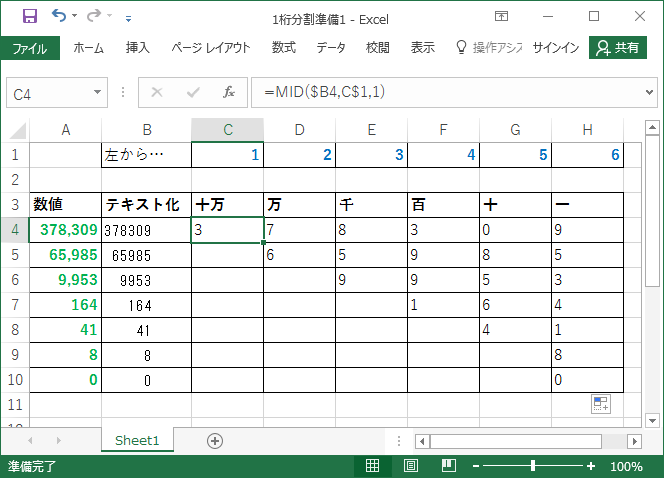
次にセルC4に
=MID($B4,C$1,1)
という関数を作成してH列まで、10行目までコピーします。
B列の値から1行目に記載した位置にある文字列を1文字分だけ取り出しています。
MID関数は(文字列,開始位置,文字数)という書式となります。
引数「文字列」にはB列の値を採用しています($B4)。
引数「開始位置」には1行目に入力した値を採用しています(C$1)。
取り出すのは1文字分ですね。
コメント